MDPO: Customized Direct Preference Optimization with a Metric-based Sampler for Question and Answer Generation
Jan 1, 2025· ,,,,·
0 min read
,,,,·
0 min read
Yihang Wang
Bowen Tian
Yueyang Su
Yixing Fan
Jiafeng Guo
Abstract
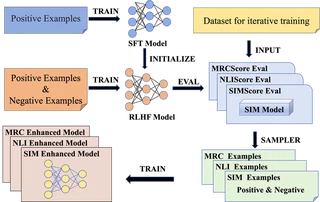
With the extensive use of large language models, automatically generating QA datasets for domain-specific fine-tuning has become crucial. However, considering the multifaceted demands for readability, diversity, and comprehensiveness of QA data, current methodologies fall short in producing high-quality QA datasets. Moreover, the dependence of existing evaluation metrics on ground truth labels further exacerbates the challenges associated with the selection of QA data. In this paper, we introduce a novel method for QA data generation, denoted as MDPO. We proposes a set of unsupervised evaluation metrics for QA data, enabling multidimensional assessment based on the relationships among context,question and answer. Furthermore, leveraging these metrics, we implement a customized direct preference optimization process that guides large language models to produce high-quality and domain-specific QA pairs. Empirical results on public datasets indicate that MDPO`s performance substantially surpasses that of state-of-the-art methods.
Type
Publication
Proceedings of the 31st International Conference on Computational Linguistics (COLING 2025)

Authors
Yihang Wang
(he/him)
MEng Artificial Intelligence
I am currently a master’s student at the Institute of Computing Technology, Chinese Academy of Sciences, with a research focus on representation learning and information retrieval. I am passionate about exploring fundamental challenges in Natural Language Processing and related areas. I possess strong self-learning capabilities, solid research and engineering practice experience, effective communication skills, and a positive, collaborative attitude. I have also accumulated rich research experience through participation in multiple academic projects.