QUITO: Accelerating Long-Context Reasoning through Query-Guided Context Compression
Jul 1, 2024· ,,,·
0 min read
,,,·
0 min read
Wenshan Wang
Yihang Wang
Yixing Fan
Huaming Liao
Jiafeng Guo
Abstract
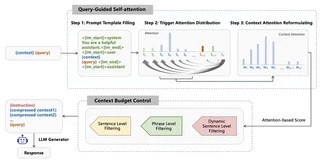
In-context learning (ICL) capabilities are foundational to the success of large language models (LLMs). Recently, context compression has attracted growing interest since it can largely reduce reasoning complexities and computation costs of LLMs. In this paper, we introduce a novel Query-gUIded aTtention cOmpression (QUITO) method, which leverages attention of the question over the contexts to filter useless information. Specifically, we take a trigger token to calculate the attention distribution of the context in response to the question. Based on the distribution, we propose three different filtering methods to satisfy the budget constraints of the context length. We evaluate the QUITO using two widely-used datasets, namely, NaturalQuestions and ASQA. Experimental results demonstrate that QUITO significantly outperforms established baselines across various datasets and downstream LLMs, underscoring its effectiveness.
Type
Publication
The 30th China Conference on Information Retrieval (CCIR 2024)

Authors
Yihang Wang
(he/him)
MEng Artificial Intelligence
I am currently a master’s student at the Institute of Computing Technology, Chinese Academy of Sciences, with a research focus on representation learning and information retrieval. I am passionate about exploring fundamental challenges in Natural Language Processing and related areas. I possess strong self-learning capabilities, solid research and engineering practice experience, effective communication skills, and a positive, collaborative attitude. I have also accumulated rich research experience through participation in multiple academic projects.